
赵晓田 Xiaotian Zhao
I'm a fourth-year Ph.D. candidate of iCAS Lab at Shanghai Jiao Tong University (SJTU), advised by Prof. Xinfei Guo. I received the B.S. degree in computer science and technology from Xidian University in 2022.
My research focuses on EDA optimizing algorithms, with a primary interest in macro placement, rectilinear floorplanning and 3DIC for high-performance chip design. I also work on mixed-precision quantization for Edge AI, aiming to balance efficiency and accuracy on resource-constrained devices. In the future, I will continue to focus on optimizing algorithms in EDA placement and further integrating them with RL and LLMs.
xiaotian.zhao@sjtu.edu.cn
TTTiko_Z
News
[2026-01-28] 😻 Updated my personal website with a new design!
[2026-01-25] 🥳 One paper (first author) on the dataflow-driven macro placement optimization is accepted by ACM TODAES which is a top-tier journal in the field of EDA!
Research
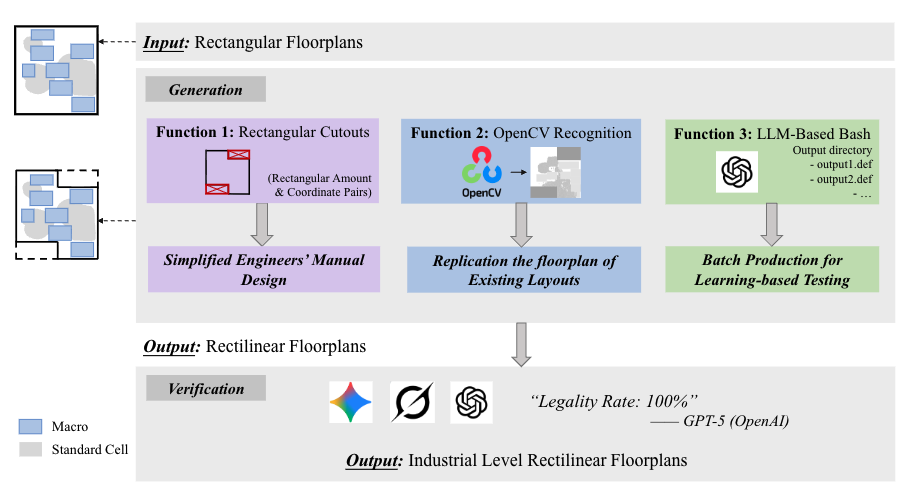
This paper introduces R-Zoo, a comprehensively developed and rigorously validated benchmark dataset of rectilinear floorplans designed for research in electronic design automation (EDA) and physical chip design.
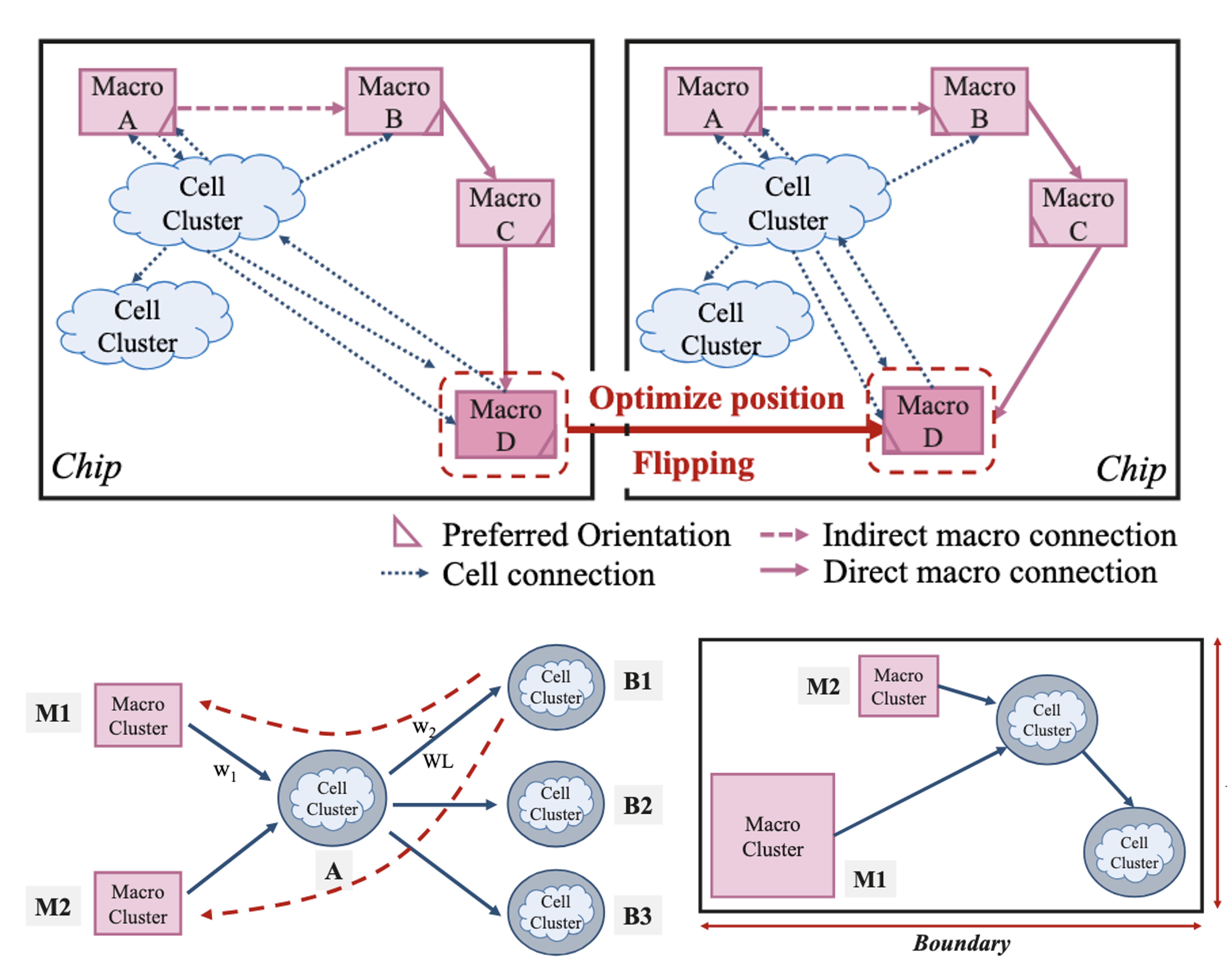
In this work, we propose DARE, which extracts hidden connections between macros and standard cells and incorporates a series of algorithms to enrich dataflow awareness, integrating them into placement constraints for improved macro placement. To further optimize placement results, we introduce two fine-tuning steps: (1) congestion optimization by taking macro area into consideration, and (2) flipping decisions to determine the optimal macro orientation based on the extracted dataflow informatio
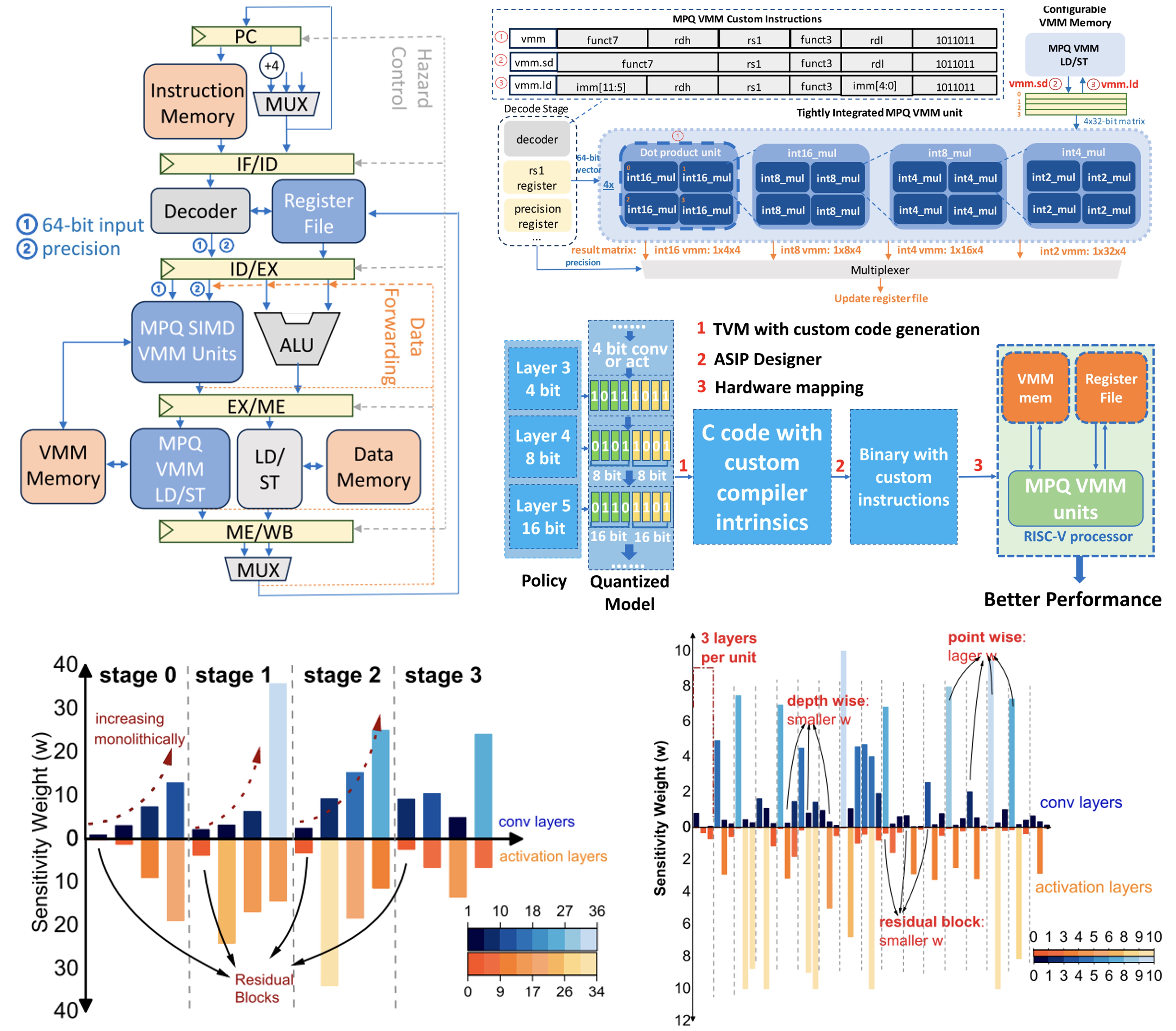
In this paper, we propose the tight integration of versatile MPQ inference units supporting INT2-INT8 and INT16 precisions, which feature a hierarchical multiplier architecture, into a RISC-V processor pipeline through micro-architecture and Instruction Set Architecture (ISA) co-design.
In this study, we identify the necessity of macro-cell connection awareness for high-quality macro placement and propose a novel methodology to extract all “hidden” relationships efficiently among macros and cell clusters.
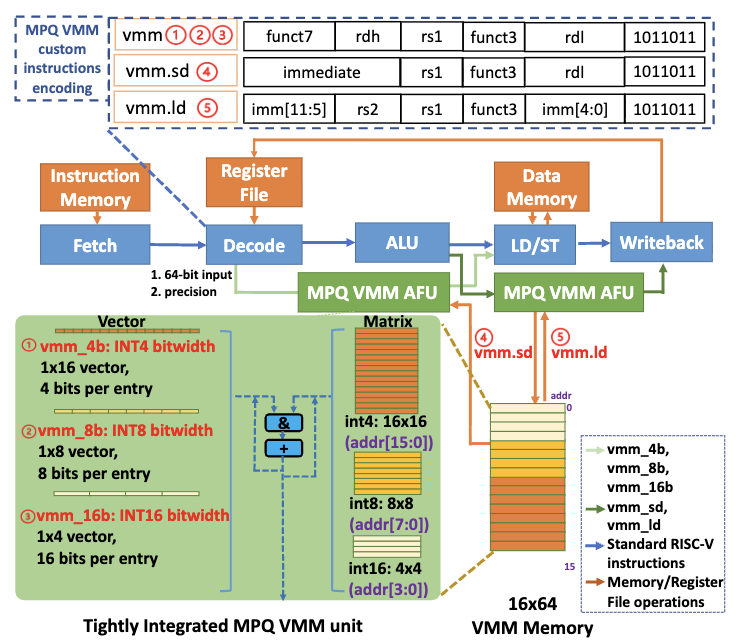
In this work, we propose a novel MPQ search algorithmthat obtains an optimal scheme by “sampling” layer-wise sensi-tivity with respect to a newly proposed metric that incorporatesboth accuracy and proxy of hardware cost. To further efficientlydeploy post-training MPQ on edge chips, we propose to tightly inte-grate the quantized inference units as part of the processor pipelinethrough micro-architecture and Instruction Set Architecture (ISA)co-design.
Hobby
© 2026 Xiaotian Zhao. Last updated: Mar 2026
